At a high level, Control-Flow Integrity (CFI) restricts the control-flow of an application to valid execution traces. CFI enforces this property by monitoring the program at runtime and comparing its state to a set of precomputed valid states. If an invalid state is detected, an alert is raised, usually terminating the application. As such, CFI belongs to the class of defenses that leverage runtime monitors to detect specific attack vectors (control-flow hijacks for CFI), and then flag exploit attempts at runtime. Other examples of runtime monitors include, e.g., ASan (Address Sanitizer, targeting spatial memory corruption), UBSan (Undefined Behavior Sanitizer, targeting undefined behavior in C/C++), or DangNull (targeting temporal memory corruption). Most of these monitors target development settings, detecting violations when testing the program. CFI, on the other hand, is an active defense mechanism and all modern compilers, e.g., GCC, LLVM, or Microsoft Visual Studio implement a form of CFI with low overhead but different security guarantees.
CFI detects control-flow hijacking attacks by limiting the targets of control-flow transfers. In a control-flow hijack attack an attacker redirects the control-flow of the application to locations that would not be reached in a benign execution, e.g., to injected code or to code that is reused in an alternate context.
Since the initial idea for the [1] defense mechanism and the first (closed source) prototype were presented in 2005 a plethora of alternate CFI-style defenses were propose and implemented. While all these alternatives slightly change the underlying enforcement or analysis, they all try to implement the CFI policy. The goal of this blog post is neither to look at differences between individual CFI mechanisms as we did in [2] (see this paper for an exhaustive enumeration of related work in the area of CFI) nor to compare CFI against alternate mechanisms as we did in [3], but to explain what CFI is, what it can do, and what its limits are.
Any CFI mechanism consists of two abstract components: the (often static) analysis component that recovers the Control-Flow Graph (CFG) of the application (at different levels of precision) and the dynamic enforcement mechanism that restricts control flows according to the generated CFG.
The following sample code shows a simple program with 5 functions. The foo function uses a function pointer and the CFI mechanisms injects both a forward-edge and a backward-edge check. The function pointer either points to bar or baz. Depending on the forward-edge analysis, different sets of targets are allowed at runtime.
void bar();
void baz();
void buz();
void bez(int, int);
void foo(int usr) {
void (*func)();
// func either points to bar or baz
if (usr == MAGIC)
func = bar;
else
func = baz;
// forward edge CFI check
// depending on the precision of CFI:
// a) all functions {bar, baz, buz, bez, foo} are allowed
// b) all functions with prototype "void (*)()" are allowed,
// i.e., {bar, baz, buz}
// c) only address taken functions are allowed, i.e., {bar, baz}
CHECK_CFI_FORWARD(func);
func();
// backward edge CFI check
CHECK_CFI_BACKWARD();
}
Control-Flow Transfer Primer
Instructions on an architecture can be grouped into control-flow transfer instructions and computational instructions. Computational instructions are executed in sequence (one after the other), while control-flow transfer instructions change control-flow in a specific way, conditionally or unconditionally redirecting control-flow to a specific (code) location.
Control-flow transfer instructions can be further grouped into direct and indirect control-flow transfer instructions. The target of indirect control-flow transfers depends on the runtime value, e.g., of a register or a memory value, compared to direct control-flow transfers where the target is usually encoded as immediate offset in the instruction itself.
Direct control-flow transfers are straight-forward to protect as, on most architectures, executable code is read-only and therefore the target cannot be modified by an attacker (even with arbitrary memory corruption as the write protection bit must first be disabled). These direct control-flow transfers are therefore protected through the read-only permission of individual memory pages and the protection is enforced (at no overhead) by the underlying hardware (the memory management unit). CFI assumes that executable code is read-only, otherwise an attacker could simply overwrite code and remove the runtime monitors.
Indirect control-flow transfers are further divided into forward-edge control-flow transfers and backward-edge control-flow transfers. Forward-edge control-flow transfers direct code forward to a new location and are used in indirect jump and indirect call instructions, which are mapped at the source code level to, e.g., switch statements, indirect calls, or virtual calls. The backward-edge is used to return to a location that was used in a forward-edge earlier, e.g., when returning from a function call through a return instruction. For simplicity, we leave interrupts, interrupt returns, and exceptions out of the discussion.
Generating Control-Flow Graphs
A CFG is a graph that covers all valid executions of the program. Nodes in the graph are locations of control-flow transfers in the program and edges encode reachable targets. The CFG is an abstract concept and the different existing CFI mechanisms use different approaches to generate the underlying CFGs using both static and dynamic analysis, relying on either the binary or source code.
For forward edges, the CFG generation enumerates all possible targets, often leveraging information from the underlying source language. Switch statements in C/C++ are a good example as the different targets are statically known and the compiler can generate a fixed jump table and emit an indirect jump with a bound check to guarantee that the target used at runtime is one of the valid targets in the switch statement.
For indirect function calls through a function pointer, the underlying analysis becomes more complicated as the target may not be known a-priori. Common source-based analyses use a type-based approach and, looking at the function prototype of the function pointer that is used, enumerate all matching functions. Different CFI mechanisms use different forms of type equality, e.g., any valid function, functions with the same arity (number of arguments), or functions with the same signature (arity and equivalence of argument types). At runtime, any function with matching signature is allowed.
Just looking at function prototypes likely yields several collisions where functions are reachable that may never be called in practice. The analysis therefore over-approximates the valid set of targets. In practice, the compiler can check which functions are address taken, i.e., there is a source line that generates the address of the function and stores it. The CFI mechanism may reduce the number of allowed targets by intersecting the sets of equal function prototypes and the set of address taken functions.
For virtual calls, i.e., indirect calls in C++ that depend on the type of the object and the class relationship, the analysis can further leverage the type of the object to restrict the valid functions, e.g., all object constructors have the same signature but only the subset constructors of related classes are feasible.
So far, the constructed CFG is stateless, i.e., the context of the execution is not considered and each control-flow transfer is independent of all others. On one hand, at runtime only one target is allowed for any possible transfer, namely the target address currently stored at the memory location of the code pointer. CFG construction, on the other hand, over-approximates the number of valid targets with different granularities, depending on the precision of the analysis. Some mechanisms take path constraints into consideration and check (for a limited depth) if the path taken through the application is feasible by using a dynamic analysis approach that validates the current execution. So far, only few mechanisms look at the path context as this incurs dynamic tracking costs at runtime.
Enforcing CFI
CFI can be enforced at different levels. Sometimes the analysis phase (CFG construction) and enforcement phase even overlap, e.g., when considering path constraints. Most mechanisms have two fundamental mechanisms, one for forward-edge transfers and one for backward-edge transfers.
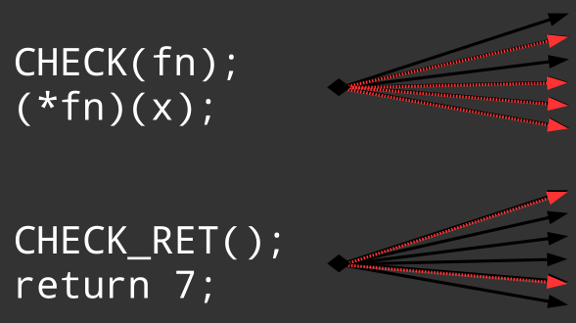
The figure shows how CFI restricts the set of possible target locations by executing a runtime monitor that validates the target according to the constructed set of allowed targets. If the observed target is not in that set, the program terminates.
For forward-edge transfers, the code is often instrumented with some form of equivalence check. The check ensures that the target observed at runtime is in the set of valid targets. This can be done through a full set check or a simple type comparison that, e.g., hashes function prototypes and checks if the hash for the current target equals the expected hash at the callsite. The hash for the function can be embedded inline in the function, before the function, or in an orthogonal metadata table.
Backward-edge transfers are harder to protect as, when using the same approach, the attacker may redirect the control-flow to any valid callsite when returning from a function. Strong backward-edge protections therefore leverage the context through the previously called functions on the stack. A mechanism that enforces stack integrity ensures that any backward-edge transfers can only return to the most recent prior caller. This property can be enforced by storing the prior call sites in a shadow stack or guaranteeing memory safety on the stack, i.e., if the return instructions cannot be modified then stack integrity trivially holds. Backward-edge control-flow enforcement is "easier" than forward-edge, as the function calls and returns form a symbiotic relationship that can be leveraged in the design of the defense, i.e., a function return always returns to the location of the previous call. Such a relationship does not exist for the forward-edge.
Summary
If implemented correctly, CFI is a strong defense mechanism that restricts the freedom of an attacker. Attackers may still corrupt memory and data-only attacks are still in scope. For the forward-edge, a strong mechanism must consider language-specific semantics to restrict the set of valid targets as much as possible. Additionally, most mechanisms for the forward-edge are stateless and allow an attacker to redirect control-flow to any valid location as identified by the CFG construction. Limiting the size of the target sets constrains the attacker on the forward edge. For the backward edge, a context-sensitive approach that enforces stack integrity guarantees full protection.
| [1] | Control-Flow Integrity. Martin Abadi, Mihai Budiu, Ulfar Erlingsson, Jay Ligatti. In CCS'05 |
| [2] | Control-Flow Integrity: Precision, Security, And Performance. Nathan Burow, Scott A. Carr, Stefan Brunthaler, Mathias Payer, Joseph Nash, Per Larsen, Michael Franz |
| [3] | On differences between the CFI, CPS, and CPI properties. Mathias Payer and Volodymyr Kuznetsov |